
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 삼정kpmg pt면접
- python
- gensim
- 삼정kpmg 취업
- 후기
- 형태소분석
- 역검 전략게임
- 역검 결과표
- 삼정kpmg 서류
- lda
- 역검 합격 꿀팁
- MYSQL
- 프로그래머스
- 역검 전략게임 꿀팁
- ai역검 합격
- pyLDAvis
- 오류
- mecab
- 잡다 ai역검
- 파이썬
- 서비스
- join
- 코딩테스트
- 컨설팅 면접
- 토픽모델링
- SQL
- kpmg 인성검사
- 잡다 ai역량검사
- 삼정kpmg mc4
- nlp
Archives
- Today
- Total
쥬니어 기획자
[NLP/토픽모델링] 리뷰 분석 - LDA 모델링, 하이퍼파라미터 튜닝 본문
반응형
지난 게시글에서 집닥 인테리어 고객 후기 데이터를 크롤링하여 데이터프레임으로 추출하였습니다.
이번 게시글에서는 LDA 토픽 모델링을 토대로 집닥 인테리어 후기를 분석해보겠습니다.
1. 텍스트 전처리
import numpy as np
import pandas as pd
from eunjeon import Mecab
mecab = Mecab(dicpath='C:/mecab/mecab-ko-dic')
import re
from collections import Counter
이전 게시물에서 크롤링을 통해 얻은 집닥 인테리어 후기 데이터를 가지고 옵니다.
data = pd.read_csv("집닥 리뷰.csv")
총 510개의 리뷰 데이터에서 한국어 텍스트만 보기 위해 텍스트 정규화를 진행하였습니다.
data['reviews'] = data['reviews'].apply(lambda x: re.sub('[^가-힣 ]', '', str(x)))
이후 문장 토큰화를 진행해줍니다. 저는 Mecab 태그 중 NNP(고유명사),NNG(일반명사)만 추출해서 확인하려 합니다.
reviews = data['reviews']
review_tokenized = []
for document in reviews:
# 형태소 분석 결과를 리스트로 저장
result = mecab.pos(document)
# 'NNP' 또는 'NNG'인 경우만 추출하여 리스트에 추가
selected_words = [word for word, pos in result if pos in ['NNP','NNG']]
# 결과를 전체 리스트에 추가
review_tokenized.append(selected_words)
# 결과 출력
print(review_tokenized)
이 외에 한 글자 단어, 너무 빈번하게 등장하는 의미가 없는 단어를 제외해줍니다.
stopword_vocab = ['수','것','시','이','안','더,','때','등','듯','분','부분','업체','후','곳','말','습','존']
#불용어 제거
def remove_stopwords(text):
temp2 = []
for j in range(len(text)) :
meaningful_words = [w for w in text[j] if not w in stopword_vocab]
temp2.append(meaningful_words)
return temp2
review_prep_pos=remove_stopwords(review_tokenized)
여기까지 기본 텍스트 전처리를 마쳤습니다 야호
2. LDA 토픽모델링
토픽모델링 시 필요한 패키지를 import해줍니다.
import time
import gensim
from gensim import corpora
import pyLDAvis.gensim
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as plt
텍스트 정제가 끝난 리뷰 데이터 리스트를 활용해 딕셔너리와 코퍼스를 만들어줍니다.
dictionary = corpora.Dictionary(review_prep_pos)
corpus = [dictionary.doc2bow(review) for review in review_prep_pos]
epoch 수 정하기 (coherence,Perplexity)
coherences=[]
perplexities=[]
passes=[]
warnings.filterwarnings('ignore')
for i in range(1,31):
ntopics, nwords = 200, 100
tic = time.time()
lda4 = gensim.models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=ntopics, iterations=400, passes=i)
cm = CoherenceModel(model=lda4, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
coherences.append(coherence)
perplexities.append(lda4.log_perplexity(corpus))
print(f'ntopics: {ntopics}, Coherence: {coherence}, Perplexity: {lda4.log_perplexity(corpus)}, Time: {time.time() - tic}\n')
# Plotting
plt.figure(figsize=(10, 6))
# Plot Coherence
plt.subplot(2, 1, 1)
plt.plot(range(1, 31), coherences, marker='o')
plt.title('Coherence vs. Epoch')
plt.xlabel('Number of Epoch')
plt.ylabel('Coherence Score')
# Plot Perplexity
plt.subplot(2, 1, 2)
plt.plot(range(1, 31), perplexities, marker='o', color='r')
plt.title('Perplexity vs. Epoch')
plt.xlabel('Number of Epoch')
plt.ylabel('Perplexity Score')
plt.tight_layout()
plt.show()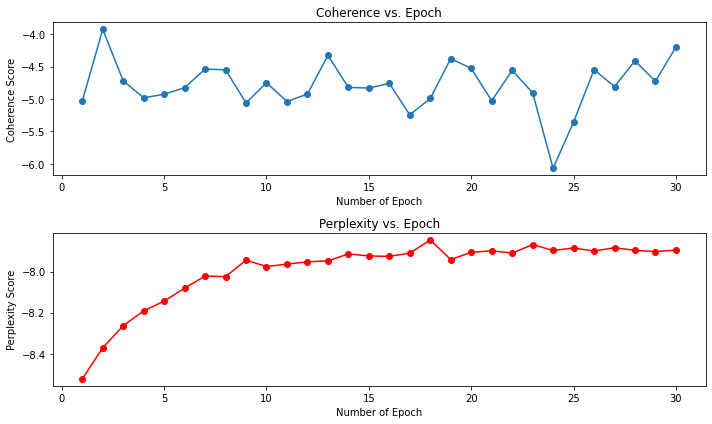
토픽 수 정하기
coherencesT=[]
perplexitiesT=[]
passes=[]
warnings.filterwarnings('ignore')
for i in range(2,30):
ntopics = i
nwords = 100
tic = time.time()
lda4 = gensim.models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=ntopics, iterations=400, passes=13)
cm = CoherenceModel(model=lda4, corpus=corpus, coherence='u_mass')
coherence = cm.get_coherence()
coherencesT.append(coherence)
perplexitiesT.append(lda4.log_perplexity(corpus))
print(f'ntopics: {ntopics}, Coherence: {coherence}, Perplexity: {lda4.log_perplexity(corpus)}, Time: {time.time() - tic}\n')
# Plotting
plt.figure(figsize=(10, 6))
# Plot Coherence
plt.subplot(2, 1, 1)
plt.plot(range(2, 30), coherencesT, marker='o')
plt.title('Coherence vs. Number of Topics')
plt.xlabel('Number of Topics')
plt.ylabel('Coherence Score')
# Plot Perplexity
plt.subplot(2, 1, 2)
plt.plot(range(2, 30), perplexitiesT, marker='o', color='r')
plt.title('Perplexity vs. Number of Topics')
plt.xlabel('Number of Topics')
plt.ylabel('Perplexity Score')
plt.tight_layout()
plt.show()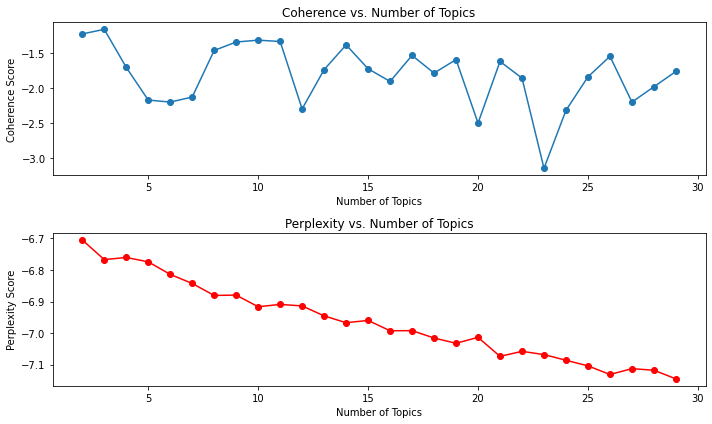
최적의 반복 수는 13, 최적의 토픽수는 10개로 조정 후 모델링을 진행해보겠습니다.
NUM_TOPICS = 10 # 토픽 개수는 하이퍼파라미터
PASSES = 13
모델 학습
def lda_modeling(review_prep):
# 단어 인코딩 및 빈도수 계산
dictionary = corpora.Dictionary(review_prep)
corpus = [dictionary.doc2bow(review) for review in review_prep]
# LDA 모델 학습
model = gensim.models.ldamodel.LdaModel(corpus,
num_topics = NUM_TOPICS,
id2word = dictionary,
passes = PASSES)
return model, corpus, dictionary
model, corpus, dictionary = lda_modeling(review_prep_pos)
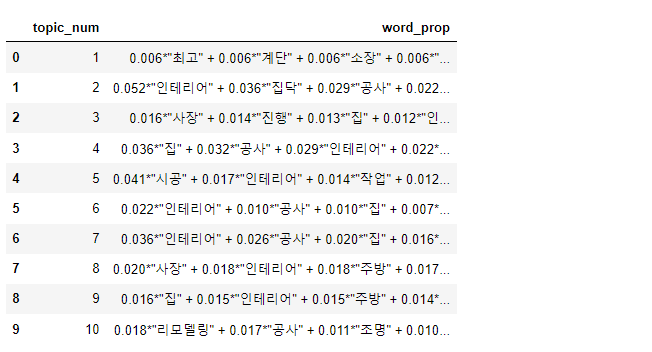
토픽 별 구성 단어 비율 출력
def print_topic_prop(topics):
topic_values = []
for topic in topics:
topic_value = topic[1]
topic_values.append(topic_value)
topic_prop = pd.DataFrame({"topic_num" : list(range(1, NUM_TOPICS + 1)), "word_prop": topic_values})
topic_prop.to_excel('./zipdoc_topic_prop.xlsx')
display(topic_prop)
NUM_WORDS = 10
topics = model.print_topics(num_words = NUM_WORDS)
print_topic_prop(topics)
위 코드를 실행하면 각 토픽들이 어떤 단어들로 구성되어 있는지 확인할 수 있습니다.
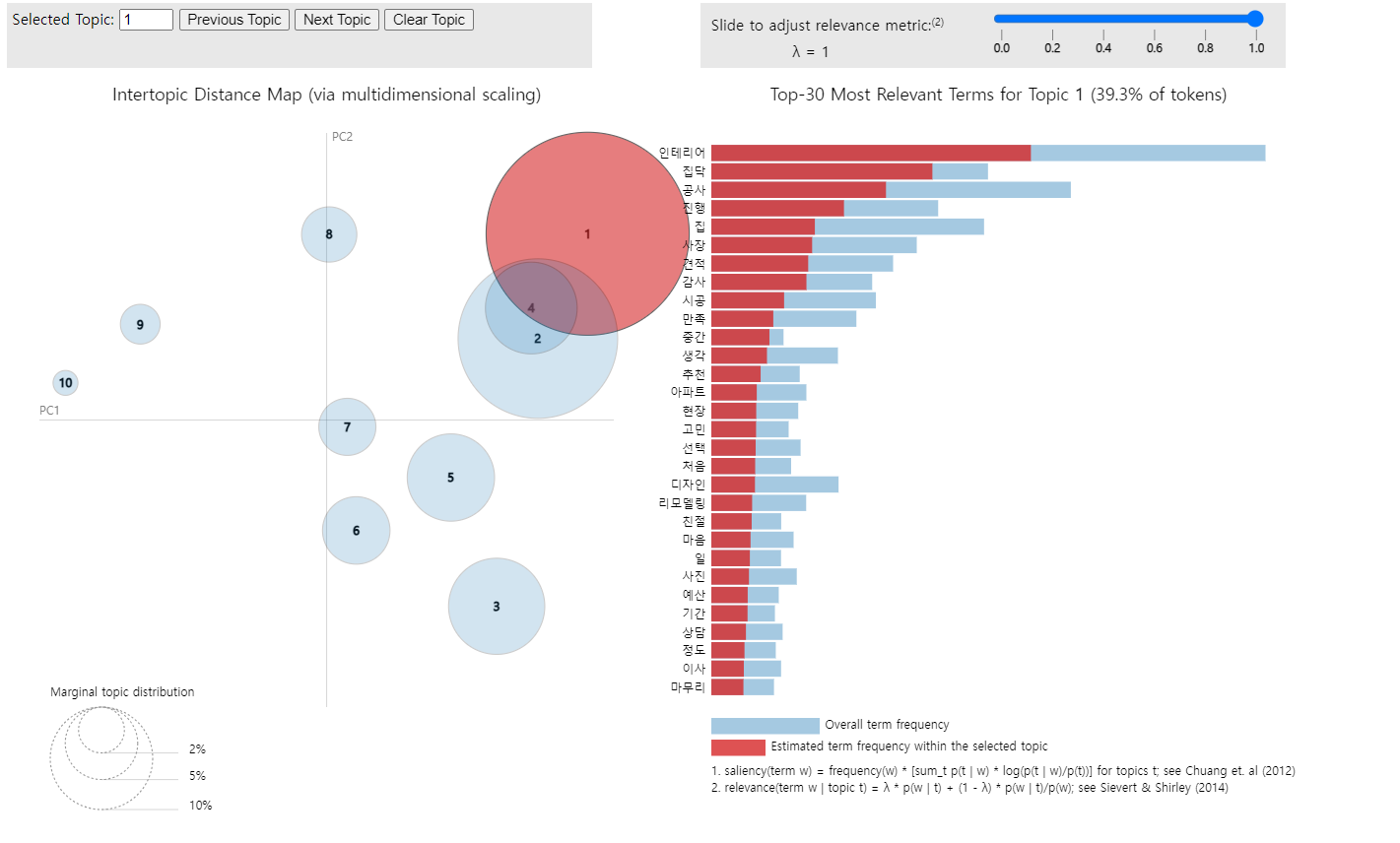
LDA 토픽 모델링 결과 시각화
def lda_visualize(model, corpus, dictionary):
pyLDAvis.enable_notebook()
result_visualized = pyLDAvis.gensim.prepare(model, corpus, dictionary)
pyLDAvis.display(result_visualized)
# 시각화 결과 저장
RESULT_FILE = './zipdoc_lda_result.html'
pyLDAvis.save_html(result_visualized, RESULT_FILE)
lda_visualize(model, corpus, dictionary)
위 코드를 실행하면 파이썬 파일이 있는 경로 내에 시각화 html 파일이 생성됩니다.
반응형
'python' 카테고리의 다른 글
| [NLP/토픽모델링] 리뷰 분석 - LDA 결과 해석 (0) | 2024.03.26 |
|---|---|
| [파이썬/NLP] 텍스트 전처리 - 정제 및 정규화 feat.replace,re (0) | 2024.02.16 |
| [파이썬/크롤링] 집닥 고객 후기 크롤링 with Selenium, BeautifulSoup (0) | 2024.02.14 |
| [NLP/mecab] 품사 태그 (0) | 2024.02.14 |
| [파이썬/NLP] 형태소 분석, 노래 가사 워드클라우드 feat.Mecab,Okt,kkma (1) | 2024.01.25 |
'python' Related Articles
more



